Is it a velutina or a crabro wasps? My second train model.
I will explain my learning process and experience with my second contact with my own training model of lesson 2, Production.
## The data: download and preparation
I have just started the second lesson of the Fastai course. In this case, the question was to make a model that predicts whether an image is a velutine wasp or a goat wasp. And then put the model into production using Hugging Spaces.
The first thing I did was, I downloaded a test image of a velutine wasp using the ddg() function:
ims = search_images_ddg('wasp vespa velutina')
len(ims)
dest = 'images/velutina.jpg'.
download_url(ims[0], dest, show_progress= True)
im = Image.open(dest)
im.to_thumb(150,150)
Once I had verified that the opened image was indeed that of a velutine wasp, I created the directories to host the downloaded images.
avispas_types = 'wasp vespa velutina', 'wasp vespa crabro', 'wasp vespa velutina', 'wasp vespa crabro'.
path = Path('vespas')
if not path.exists():
path.mkdir()
for o in wasp_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results= search_images_ddg(f'{o} vespa')
download_images(dest, urls=results)
Once the directories and downloaded images have been created, I proceed to delete the wrong ones and unlink them from the project.
I prepare the data with the Fastai function “DataBlock()” and pass them to a dataloader.
I check how some images look like with the function show_batch(max_n=8, nrows=2) and rescale the images.
I finish the first part of my model by training the data with a resnet18 and a fine_tune(4) and creating a confusion matrix.
At this point, I run into a problem. I don’t know if it’s a configuration problem or if I’ve done something wrong in the algorithm. When I included the following instruction “interp.plot_top_losses(5, nrows=1) The text with the result information is unreadable because it mounts one text on top of another.
I consulted this problem on the fastai forum and they gave me two solutions.
The first one, increase nrows. Because I was passing ‘nrows=1’ so all the predictions are put in that single line and as the corresponding texts are wider than the images they overlap. And what I did, was to give more space to each image by spreading them over several lines (nrows=3 let’s say).
Another thing I could do was to try passing figsize=(20,5) (playing with those values) which tells pyplot, which plots the figures, to use more space on the notebook canvas.
It doesn’t really solve much and the text would be overlapped so the reading was very difficult. I still don’t know how to solve this issue.
Putting the model into production
At this point I would like to comment on a few issues. First, I have not been able to get good quality images downloaded from ddg. The first attempt, I had searched for the Latin names of the two wasp species on which my model was based. The result was very poor as many of the downloaded images were, instead of wasps, vespa motorbikes. I changed the search criteria and searched for ‘vespa vespa velutina wasp’ and ‘vespa vespa carro wasp’. Although it improved a bit, there was still some confusion. Finally, I decided to do without the term ‘vespa’ and searched for ‘avispa velutina’ and ‘avispa crabro’. This way I managed to avoid downloading any Vespa scooter images.
One issue that I think might be interesting for a novice student like me, is that I didn’t know very well how to manage the folders created with the images on the server. For example, every time I re-downloaded images by modifying the search terms, the previously created folders remained with the same image files and were not updated with the new search criteria.
Apparently the folders created on the Colab server cannot be modified or deleted from the notebook itself. To delete them, f. ex, I used the console with the following statement:
!rm -r /content/vespas.
Another issue that gave me problems and that I couldn’t solve was the bad training results, both ‘train_loss’, ‘valid_loss’ and ‘error_rate’ returned bad values. I tried to modify the CNN first with resnet14 and then resnet50. As well as fine_tune(), with value 4 first the result was the following:
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.259244 | 5.038797 | 0.486842 | 00:07 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.220864 | 1.106514 | 0.473684 | 00:07 |
| 1 | 1.184358 | 1.731663 | 0.486842 | 00:07 |
| 2 | 1.063790 | 1.548331 | 0.486842 | 00:07 |
| 3 | 0.993660 | 1.542113 | 0.447368 | 00:07 |
With fine_tune(8) hardly changed the result.
The last part was to put the model into production. As the result of the training was not satisfactory I did not have high expectations that the application in Hugging Spaces would be efficient. As expected, already with the first image I uploaded, a very clear image of a velutine wasp, the model predicted that it was a crabo wasp with the following result:
Output:
wasp vespa crabro
vespa crabro wasp
73%
vespa velutina wasp
27%
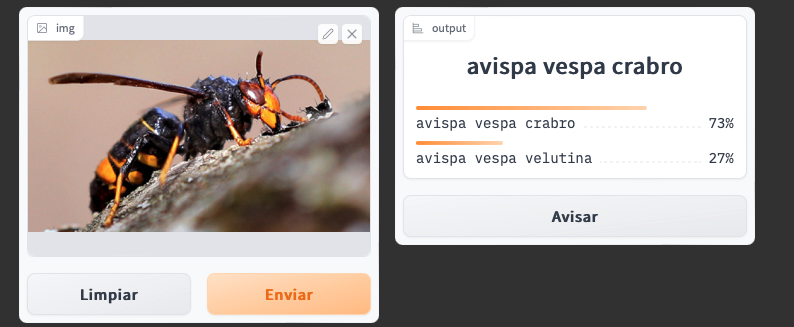 Only 27% for “avispa velutina” which was the right picture!!!
Only 27% for “avispa velutina” which was the right picture!!!
## Final conclusion
it is obvious that my model has not worked satisfactorily. The reason I think is in the data, on the one hand it is not easy for the machine to differentiate one species of wasp from another, they are quite similar although to us with our vision it seems false to distinguish. On the other hand, the downloaded data contained many dubious images, nests of both species, images containing both types of wasp and others showing species other than these two.
I assume that correct data handling is one of the essential conditions for the predictive model to work. In pre-trained models this kind of problem does not arise, but with in-house data it is a challenge to handle the correct images for the model to work.